Implementing an event-driven architecture on serverless — the Smart Parking story
Brian Granatir
SmartCloud Engineering Team Lead, Smart Parking
Part 2
In this article, we’re going to explore how to build an event-driven architecture on serverless services to solve a complex, real-world problem. In this case, we’re building a smart city platform. An overview of the domain can be found in part one. If you haven’t read part one, please go take a look now. Initial reviews are in, and critics are saying “this may be the most brilliantly composed look at modern software development; where’s dinner?” (please note: in this case the "critics" are my dogs, Dax and Kiki).Throughout this part, we’ll be slowly building up an architecture. In part three, we’ll dive deeper into some of the components and review some actual code. So let’s get to it. Where do we start? Obviously, with our input!
Zero step: defining our domain
Before we begin, let’s define the domain of a smart city. As we learned in the previous post, defining the domain means establishing a clear language and terminology for referencing objects and processes in our software system. Of course, creating this design is typically more methodical, iterative, and far more in-depth. It would take a genius to just snap and put an accurate domain at the end of a blog post (it’s strange that I never learned to snap my fingers, right?).Our basic flow, for this project is a network of distributed IoT (Internet of Things) devices that send periodic readings that are used to define the frames of larger correlated events throughout a city.
- Sensor - electronic device that's capable of capturing and reporting one or more specialized readings
- Gateway - an internet-connected hub that's capable of receiving readings from one or more sensors and sending these packages to our smart cloud platform
- Device - the logical combination of a sensor and its reporting gateway (used to define a clear split between the onramp from processing)
- Readings - key-value pairs (e.g., { temperature: 35, battery: "low" } ) sent by sensors
- UpdatedReadings - the command to update readings for a specific device
- ReadingsUpdated - the event that occurs in our system when new readings are received from a device (response to a UpdateReadings command)
- Frame - a collection of correlated / collocated events (typically ReadingsUpdated) used to drive business logic through temporal reasoning [lots more on this later]
- Device Report - an analytic view of devices and their health metrics (typically used by technicians)
- Event Report - an analytic view of frames (typically used by business managers) If we connect all of these parts together in a diagram, and add some serveless glue (parts in bold), we get a nice overview of our architecture:
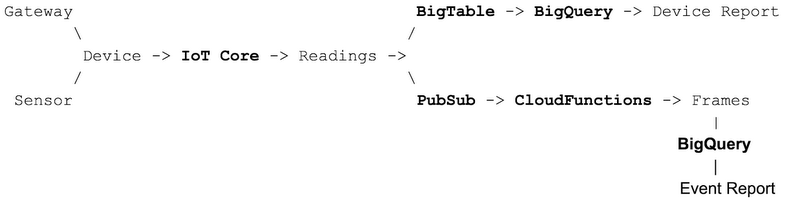
Of course, there's a fair bit of missing glue in the above diagram. For example, how do we take an UpdateReadings command and get it into Bigtable? This is where my favorite serverless service comes into play: Cloud Functions! How do we install devices? Cloud Functions. How do we create organizations? Cloud Functions. How do we access data through an API? Cloud Functions. How do we conquer the world? Cloud Functions. Yep, I’m in love!
Alright, now we have our baseline, let’s spend the rest of this post exploring just how we go about implementing each part of our architecture and dataflows.
First step: inbound data
Our smart city platform is nothing more than a distributed network of internet-connected (IoT) devices. These devices are composed of one or more sensors that capture readings and their designated gateways that help package this data and send it through to our cloud.
For example, we may have an in-ground sensor used to detect a parked car. This senor reports IR and magnetic readings that are transferred through RF (radio frequencies) to a nearby gateway. Another example is a smart trash can that monitors capacity and broadcasts when the bin is full.
The challenge of IoT-based systems has always been collecting data, updating in-field devices, and security. We could write an entire series of articles on how to deal with these challenges. In fact, the burden of this task is the reason we haven’t seen many sophisticated, generic IoT platforms. But not anymore! The problem has been solved for us by those wonderful engineers at Google. Cloud IoT Core is a serverless service offered by Google Cloud Platform (GCP) that helps you skip all the annoying steps. It’s like jumping on top of the bricks!
Wait . . . does anyone get that reference anymore? Mario Brothers. The video game for the NES. You could jump on top of the ceiling of bricks to reach a secret pipe that let you skip a bunch of levels. It was a pipe because you were a plumber . . . fighting a turtle dragon to save a princess. And you could throw fireballs by eating flowers. Trust me, it made perfect sense!
Anyway! Cloud IoT Core is the secret passage that lets you skip a bunch of levels and get to the good stuff. It scales automatically and is simple to use. Seriously, don’t spend any time managing your devices and securing your streams. Let Google do that for you.
So, sensors are observing life in our city and streaming this data to IoT Core. Where does it end up after IoT Core? In Cloud Pub/Sub, Google’s serverless queuing service. Think of it as a globally distributed subscription queue with guaranteed delivery. The result: our vast network of data streams has been converted to a series of queues that our services can subscribe to. This is our inbound pipeline. It scales nearly infinitely and requires no operation support. Think about that. We haven’t even written any code yet and we already have an incredibly robust architecture. Trust me, it took my team only a week to move over existing device onramp to IoT Core—it’s that straightforward. And how many problems have we had? How many calls at 3 AM to fix the inbound data? Zero. They should call it opsless rather than serverless!
Anyway, we got our data streaming in. So far, our architecture looks like this:

While we’re exploring a smart city platform made from IoT devices, you can use this pipeline with almost any architecture. Just replace the IoT Core box with your onboarding service and output to Pub/Sub. If you still want that joy of serverless (and no calls at 3 AM), then consider using Google Cloud Dataflow as your onramp!
What is Dataflow? It's a serverless implementation of a Hadoop-like pipeline used for the transformation and enriching of streaming or batch data. Sounds really fancy, and it actually is. If you want to know just how fancy, grab any data engineer and ask for their war stories on setting up and maintaining a Hadoop cluster (it might take awhile; bring popcorn). In our architecture, it can be used to both onramp data from an external source, to help with efficient formation of aggregates (i.e., to MapReduce a large number of events), or to help with windowing for streaming data. This is huge. If you know anything about streaming data, then you’ll know the value of a powerful, flexible windowing service.
Ok, now that we got streaming data, let’s do something with it!
Second step: normalizing streaming data
How is a trash can like a street lamp? How is a parking sensor like a barometer? How is a phaser like a lightsaber? These are questions about normalization. We have a lot of streaming data, but how do we find a common way of correlating it all?For IoT this is a complex topic and more information can be found in this whitepaper. Of course, the only whitepaper in most developers lives comes on a roll. So here is a quick summary:
How do we normalize the data streaming from our distributed devices? By converting them all to geolocated events. If we know the time and location of a sensor reading, we can start to colocate and correlate events that can lead to action. In other words, we use location and time to help use build a common reference point for everything going on in our city.
Fortunately, many (if not all devices) will already need some form of decoding / translation. For example, consider our in-ground parking sensor. Since it's transmitting data over radio frequencies, it must optimize and encode data. Decoding could happen in the gateway, but we prefer a gateway to contain no knowledge of the devices it services. It should just act as the doorway to the world wide web (for all the Generation Z folks out there, that’s what the "www." in urls stands for).
Ideally, devices would all natively speak "smart city" and no decoding or normalization would be needed. Until then, we still need to create this step. Fortunately, it is super simple with Cloud Functions.
Cloud Functions is a serverless compute offering from Google. It allows us to run a chunk of code whenever a trigger occurs. We simply supply the recipe and identify the trigger and Google handles all the scaling and compute resource allocation. In other words, all I need to do is write the 20-50 lines of code that makes my service unique and never worry about ops. Pretty sweet, huh?
So, what’s our trigger? A Pub/Sub topic. What’s our code? Something like this:
If you’re not familiar with promises and async coding in JavaScript, the above code simply does the following:
- Parse the message from Pub/Sub
- When this is done, decode the payload byte string sent by the sensor
- When this is done, wrap the decoded readings with our normalized UpdateReadings command data struct
- When this is done, send the normalized event to the Device Readings Pub/Sub
So, in summary, the second step is to normalize all our streams by converting them into commands. In this case, all sensors are sending in a command to UpdateReadings for their associated device. Why didn’t we just create the event? Why bother making a command? Remember, this is an event-driven architecture. This means that events can only be created as a result of a command. Is it nitpicky? Very. But is it necessary? Yes. By not breaking the command -> event -> command chain, we make a system that's easy to expand and test. Without it, you can easily get lost trying to track data through the system (yes, a lot more on tracking data flows later).
So our architecture now looks like this:

Data streams coming into our platform are decoded using bespoke Cloud Functions that output a normalized, timestamped command. So far, we’ve only had to write about 30 - 40 lines of code, and the best part . . . we’re almost halfway complete with our entire platform.
Now that we have commands, we move onto the real magic. . . storage. Wait, storage is magic?
Third step: storage and indexing events
Now that we've converted all our inbound data into a sequence of commands, we’re 100% into event-driven architecture. This means that now we need to address the challenges of this paradigm. What makes event-driven architecture so great? It makes sense and is super easy to extend. What makes event-driven architecture painful? Doing it right has been a pain. Why? Because you only have commands and events in your system. If you want something more meaningful you need to aggregate these events. What does that mean? Let’s consider a simple example.
Let’s say you’ve got an event-driven architecture for a website that sells t-shirts. The orders come in as commands from a user-submitted web form. Updates also come in as commands. On the backend, we store only the events. So consider the following event sequence for a single online order:
You cannot get an accurate view of the current order by looking at only one event. If you only looked at #2 (Address Changed), you wouldn’t know the item quantities. If you only looked at #3 (Quantity Change), you wouldn’t have the address.
To get an accurate view, you need to "replay" all the events for the order. In event-driven architecture, this process is often referred to as "hydrating." Alternatively, you can maintain an aggregate view of the order (the current state of the order) in the database and update it whenever a new command arrives. Both of these methods are correct. In fact, many event-driven architectures use both hydration and aggregates.
Unfortunately, implementing consistent hydration and/or aggregation isn’t easy. There are libraries and even databases designed to handle this, but that was before the wondrous powers of serverless computing. Enter Google Cloud Bigtable and BigQuery.
Bigtable is the database service that Google uses to index and search the entire internet. Let that sink in. When you do a Google search, it's Bigtable that gets you the data you need in a blink of an eye. What does that mean? Unmatched power! We’re talking about a database optimized to handle billions of rows with millions of columns. Why is that so important? Because it lets us do event-driven architecture right!
For every command we receive, we create a corresponding event that we store in Bigtable.
Wow.
This blogger bloke just told us that we store data in a database.
Genius.
Why thank you! But honestly, it's the aspects of the database that matters. This isn’t just any database. Bigtable lets us optimize without optimizing. What does that mean? We can store everything and anything and access it with speed. We don’t need to write code to optimize our storage or build clever abstractions. We just store the data and retrieve it so fast that we can aggregate and interpret at access.
Huh?
Let me give you an example that might help explain the sheer joy of having a database that you cannot outrun.
These days, processors are fast. So fast that the slowest part of computing is loading data from the disk (even SSD). Therefore, most of the world’s most performant systems use aggressive compression when interacting with storage. This means that we'll compress all writes going to disk to reduce read-time. Why? Because we have so much excess processing power, it's faster to decompress data rather than read more bytes from disk. Go back 20 years and tell developers that we would "waste time" by compressing everything going to disk and they would tell you that you’re mad. You’ll never get good performance if you have to decompress everything coming off the disk!
In fact, most platforms go a step further and use the excessive processing power to also encrypt all data going to disk. Google does this. That’s why all your data is secure at rest in their cloud. Everything written to disk is compressed AND encrypted. That goes for their data too, so you know this isn’t impacting performance.
Bigtable is very much the same thing for web services. Querying data is so fast that we can perform processing post-query. Previously, we would optimize our data models and index the heck out of our tables just to reduce query time inside the database. When the database can query across billions of rows in 6 ms, that changes everything. Now we just store and store and store and process later.
This is why storing your data in a database is amazing, if it's the right database!
So how do we deal with aggregation and hydration? We don’t. At least not initially. We simply accept our command, load any auxiliary lookups needed (often the sensor / device won’t be smart enough to know its owner or location), and then save it to Bigtable. Again, we’re getting a lot of power with very little code and effort.
But wait, there’s more! I also mentioned BigQuery. This is the service that allows us to run complex SQL queries across massive datasets (even datasets store in a non-SQL database). In other words, now that I’ve stored all this data, how do I get meaning from it? You could write a custom service, or just use BigQuery. It will let you perform queries and aggregations across terabytes of data in seconds.
So yes, for most of you, this could very well be the end of the architecture:

Seriously, that’s it. You could build any modern web service (social media, music streaming, email) using this architecture. It will scale infinitely and have a max response time for queries of around 3 - 4 seconds. You would only need to write the initial normalization and the required SQL queries for BigQuery. If you wanted even faster responses, you could target queries directly at Bigtable, but that requires a little more effort.
This is why storage is magic. Pick the right storage and you can literally build your entire web service in two weeks and never worry about scale, ops, or performance. Bigtable is my Patronus!!
Now we could stop here. Literally. We could make a meaningful and useful city platform with just this architecture. We’d be able to make meaningful reports and views on events happening throughout our city. However, we want more! Our goal is to make a smart city, one that automatically reacts to events.
Fourth step: temporal reasoning
Ok, this is where things start to get a little more complex. We have events—a lot of events. They are stored, timestamped and geolocated. We can query this data easily and efficiently. However, we want to make our system react.
This is where temporal reasoning comes in. The fundamental idea: we build business rules and insights based on the temporal relationship between grouped events. These collections of related events are commonly referred to as "intervals" or "frames." For example, if my interval is a lecture, the lecture itself can contain many smaller events:

We can also take the lecture in the context of an even larger interval, such as a work day:

And of course, these days can be held in the context of an even larger frame, like a work week.
Once we've built these frames (these collection of events), we can start asking meaningful questions. For example, "Has the average temperature been above the danger threshold for more than 5 minutes?", "Was maintenance scheduled before the spike in traffic?", "Did the vehicle depart before the parking time limit?"
For many of you, this process may sound familiar. This approach of applying business rules for streaming data has many similarities to a Complex Event Processing (CEP) service. In fact, a wonderful implementation of a CEP that uses temporal reasoning is the Drools Fusion module. Amazing stuff! Why not just use a CEP? Unfortunately, business rule management systems (BRMS) and CEPs haven't yet fully embraced the smaller, bite-size methodologies of microservices. Most of these system require a single monolithic instance that demands absolute data access. What we need is a distributed collection of rules that can be easily referenced and applied by a distributed set of autoscaling workers.
Fortunately, writing the rules and applying the logic is easy once you have the grouped events. Creating and extending these intervals is the tricky part. For our smart city platform, this means having modules that define specific types of intervals and then adds any and all related events.
For example, consider a parking module. This would take the readings from sensors that detect the arrival and departure of a vehicle and create a larger parking interval. An example of a parking interval might be:

We simply build a microservice that listens to ReadingsUpdated events and manages creation and extension of parking intervals. Then, we're free to make a service that reacts to the FrameUpdated events and runs temporal reasoning rules to see if a new command should be created. For example, "If there's no departure 60 minutes after arrival, broadcast an IssueTicket command."
Of course, we may need to correlate events into an interval that are outside the scope of the initial sensor. In the parking example, we see "payment made." Payment is clearly not collected by the parking sensor. How do we manage this? By creating links between the interval and all known associated entities. Then, whenever a new event enters our system, we can add it to all related intervals (if the associated producer or its assigned groups are related). This sounds complex, but it's actually rather easy to maintain a complex set of linkages in Bigtable. Google does on a significant scale (like the entire internet). Of course, this would be a lot simpler if someone provided a serverless graph database!
So, without diving too much into the complexities, we have the final piece of our architecture. We collect events into common groups (intervals), maintain a list of links to related entities (for updates), and apply simple temporal reasoning (business rules) to drive system behavior. Again, this would be a nightmare without using an event-driven architecture built on serverless computing. In fact, once we get a serverless graph database and distributed BRMS, we've solved the internet (spoiler alert: we'll all change into data engineers, AI trainers and UI guys).
[BTW, for more information, please consult the work of the godfather of computer-based temporal reasoning, James F. Allen. More specifically, his whitepapers An Interval-Based Representation of Temporal Knowledge and Maintaining Knowledge about Temporal Events]
Fifth step: the extras
While everything sounds easy, there are a few details I may have glossed over. I hope you found some! You’re an engineer, of course you did. Sorry, but this part is a little technical. You can skip it if you like! Or, just email me your doubt and I’ll reply!
A quick example is how do I query a subset of devices. We have everything stored in Bigtable, but how do I look at only one group? For example, what if I only wanted to look at devices or events downtown?
This is where grouping comes in. It’s actually really easy with Bigtable. Since Bigtable is NoSQL, it means that we can have sparse columns. In other words, we can have a family called "groups" and any custom set of column qualifiers in this family per row. In other words, we let an event belong to any number of groups. We look up the current groups when the command is received for the device and add the appropriate columns. This will hopefully make more sense when we go deeper in part three.
Another area worth a passing mention is extension and testing. Why is serverless and event-driven architecture so easy to test and extend? The ease of testing comes from the microservices. Each component does one thing and does it well. It accepts either a command or an event and produces a simple output. For example, each of our event Pub/Subs has a Cloud Function that simply takes the events and stores them in Google Cloud Storage for archival purposes. This function is only 20 lines of code (mostly boilerplate) and has absolutely no impact on the performance of other parts of the system. Why no impact? It's serverless, meaning that it autoscales only for its needs. Also, thanks to the Pub/Sub queues, our microservice is taking a non-destructive replication of input (i.e., each microservice is getting a copy of the message without putting a burden on any other part of our architecture).
This zero impact is also why extension of our architecture is easy. If we want to build an entirely new subsystem, we simply branch off one of the Pub/Subs. This means a developer can rebuild the entire system if they want with zero impact and zero downtime for the existing system. I've done this [transitioned an entire architecture from Datastore to Bigtable1], and it's liberating. Finally, we can rebuild and refactor our services without having to toss out the core of our architecture—the events. In fact, since the heart of our system is events published through serverless queues, we can branch our system just like many developers branch their code in modern version control systems (i.e, Git). We simply create new ways to react to commands and events. This is perfect for introducing new team members. These noobs [technical term for a new starter] can branch off a Pub/Sub and deploy code to the production environment on their first day with zero risk of disrupting the existing system. That's powerful stuff! No-fear coding? Some dreams do come true.
BUT—and this is a big one (fortunately, I like big buts)—what about integration testing? Building and testing microservices is easy. Hosting them on serverless is easy. But how do we monitor them and, more importantly, how do we perform integration testing on this chain of independent functions? Fortunately, that's what Part Three is for. We'll cover this all in great detail there.
Conclusion
In this post, we went deep into how we can make an event-driven architecture work on serveless through the context of a smart city platform. Phew. That was a lot. Hope it all made sense (if not, drop me an email or leave a comment). In summary, modern serverless cloud services allow us to easily build powerful systems. By leveraging autoscaling storage, compute and queuing services, we can make a system that outpaces any demand and provides world-class performance. Furthermore, these systems (if designed correctly) can be easy to create, maintain and extend. Once you go serverless, you'll never go back! Why? Because it's just fun!
In the next part, we'll go even deeper and look at the code required to make all this stuff work.
1 A little more context on the refactor, for those who care to know. Google Datastore is a brillant and extremely cost-efficient database. It is noSQL like Bigtable but offers traditional-style indexing. For most teams, Datastore will be a magic bullet (solving all your scalability and throughput needs). It’s also ridiculously easy to use. However, as your data sets (especially for streaming) start to grow, you’ll find that the raw power of Bigtable cannot be denied. In fact, Datastore is built on Bigtable. Still, for most of us, Datastore will be everything we could want in a database (fast, easy and cheap, with infanite2 scaling).
2 Did I put a footnote in a footnote? Yes. Does that make it a toenote? Definitely. Is ‘infanite’ a word? Sort of. In·fa·nite (adjective) - practically infinite. Google’s serverless offerings are infanite, meaning that you’ll never hit the limit until your service goes galactic.


